
MedEvalArena
Self-generated, peer-judged framework for evaluating the medical reasoning capabilities of LLMs


1. Evolving the future of medical reasoning evaluation
Static benchmarks increasingly are saturated by the evolving reasoning capabilities of LLMs. This dynamic is illustrated by the repeated redesign of Francois Chollet’s ARC Challenge, now in its 3rd iteration (with more planned).
In contrast to ARC and similar benchmarks, medical reasoning evaluation relies on benchmarks which historically have undergone academic peer review and validation. These time- and cost-intensive processes introduce significant lag between the abilities of frontier LLMs and our understanding of their medical reasoning competence.
Although LLMs meet or exceed human performance on conventional medical assessments (MCAT, USMLE, board exams)[1-3], they perform poorer in real-world scenarios and in contexts that generally differ from LLM training corpora [4-6].
Addressing these limitations motivates the need for dynamic evaluation frameworks that adapt alongside LLMs, facilitating more timely assessment of their medical reasoning to provide a tighter feedback-loop for their improvement.
Proposed solution: Dynamic, AI-governed framework for evaluating the medical reasoning capabilities of LLMs (and humans). We propose a dynamic evaluation framework with three roles:
Generator: models generate challenging medical questions
Validator: models adjudicate question validity
Solver: models attempt validated questions
All roles are assigned symmetrically across models in a round-robin design.
2. MedEvalArena Framework
In the three step process:
LLM Quiz Generation
Quizzes are generated by each LLM using the latest top 6 SOTA families according to Artificial Analysis (cut-off date of 11/15/2025) OpenAI, XAI, Gemini, Kimi, DeepSeek, Anthropic reasoning models.
50 quiz questions are generated per LLM across a broad set of medical domains, weighted by US specialty representation1.
Quiz generation prompts asked LLMs to generate extremely hard specialty/subspecialty board questions.
LLM-as-Judge (Validator)
LLMs take turns evaluating quizzes generated by other LLMs, as well as self-generated quizzes (their own quiz) across two dimensions of validity:
logical coherence
medical accuracy
Only questions which had majority logical validity and medical accuracy score >3 on 1-5 scale were included for subsequent evaluation.
LLM evaluation (Solver).
LLMs take turns taking validated quizzes generated by other LLMs, as well as their own.
3. Results
Figure 1. LLMs had varied question validity rates.
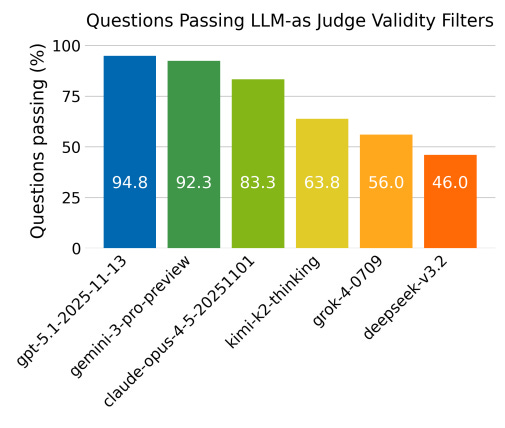
Differences were statistically significant between top 3 models compared to lower 3 models (Prem et al. 2026).
Figure 2. No significant difference in quiz-taking accuracy was found between frontier models.
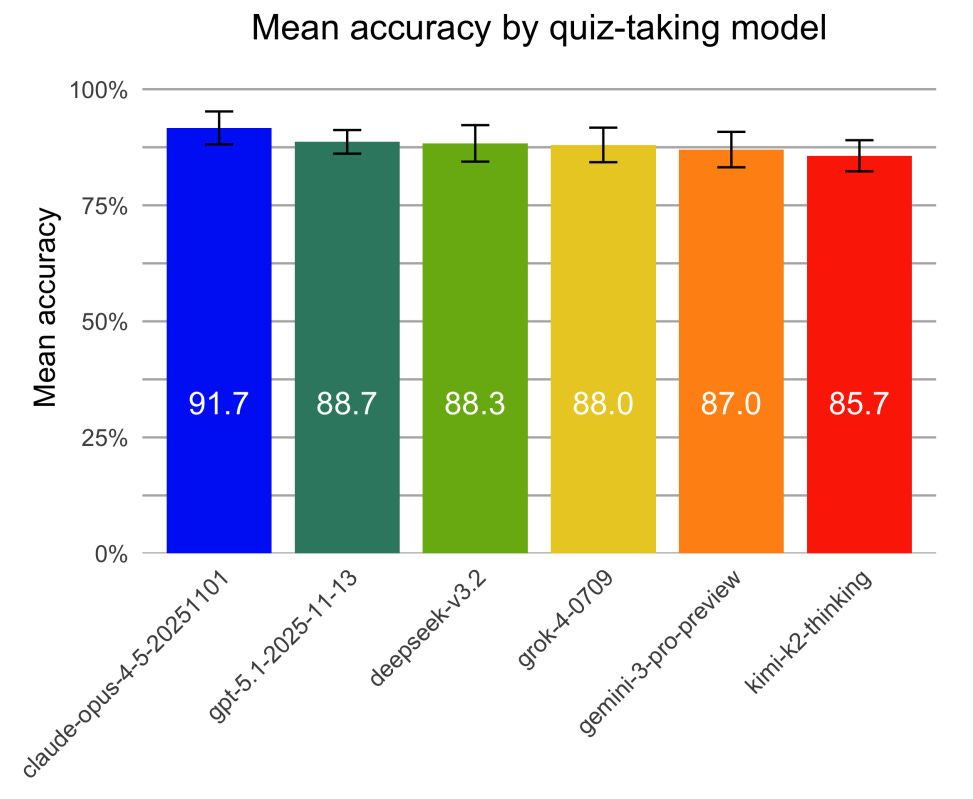
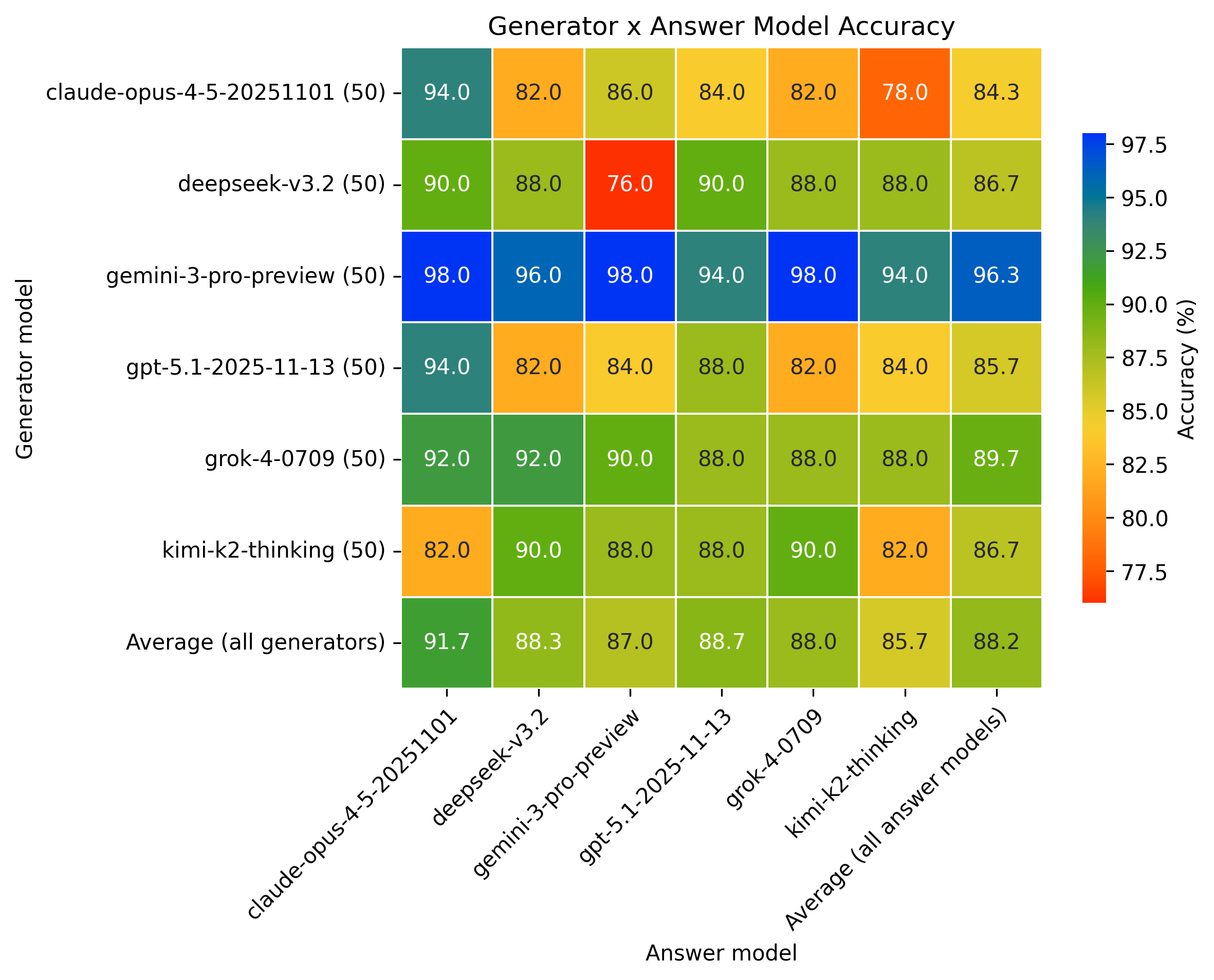
Model performance differences were assessed with GLMM (Prem et al. 2026).
Figure 3. Accuracy vs Cost per Quiz and Pareto frontier.
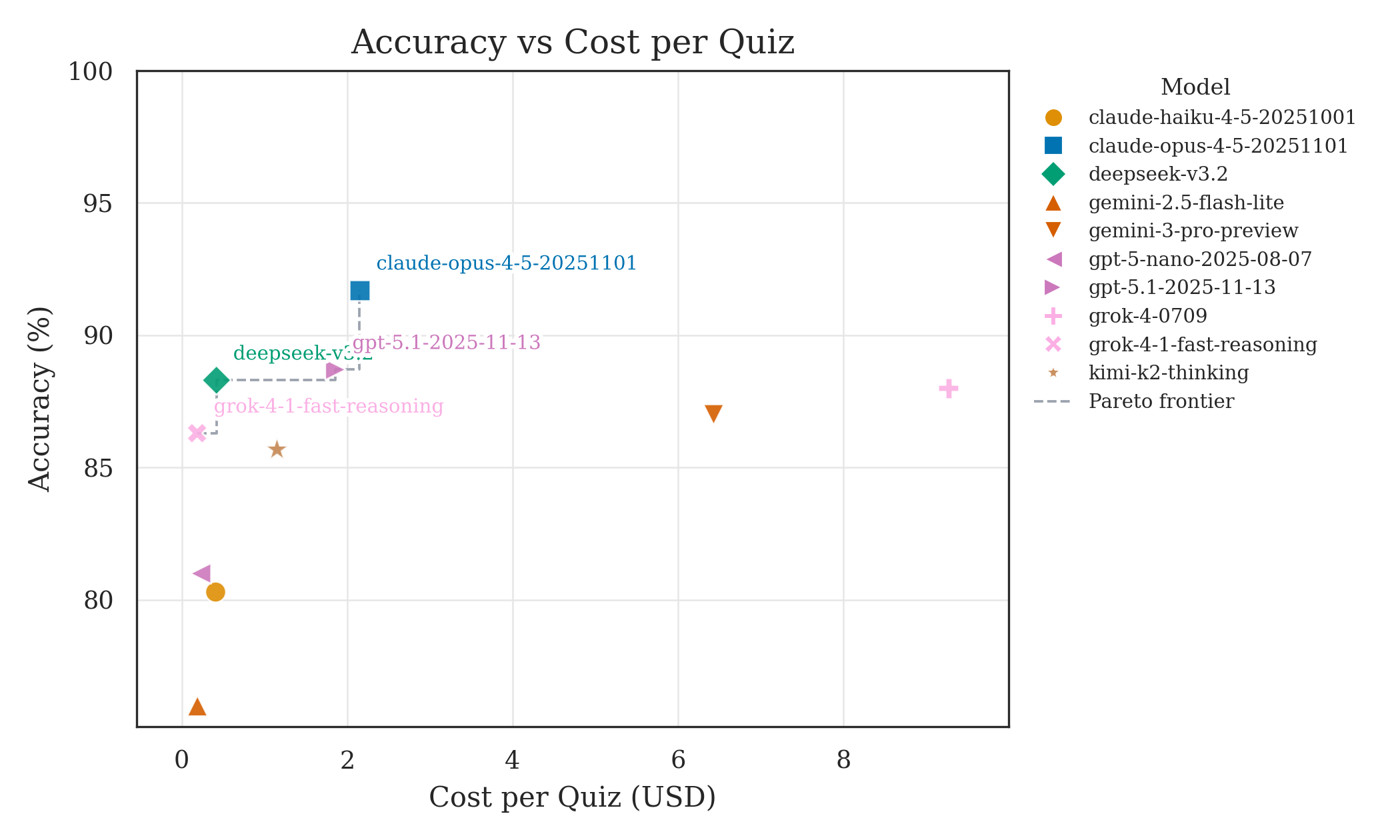
Pareto frontier models labeled.
4. Take-aways
Key findings
Frontier LLMs show convergent performance when solving validated medical reasoning tasks, despite differing costs and architectures.
In contrast, models differ substantially in their ability to generate valid medical questions.
Pareto frontier spans multiple model families.
Implication: Dynamic, model-generated evaluations may help differentiate reasoning capabilities, particularly as frontier performance saturates.
5. Read more in depth analysis in our preprint and git repo
Prem, P., Shidara, K., Kuppa, V., Wheeler, E., Liu, F., Alaa, A., & Bernardo, D. (2026). MedEvalArena: A Self-Generated, Peer-Judged Benchmark for Medical Reasoning. medRxiv. https://doi.org/10.64898/2026.01.27.26344905
Download preprint below.
MedEvalArena latest leaderboard: https://bernardolab.github.io/MedEvalArena/
6. Notes
Figures were generated with Google nano banana
References
Jiang, Lavender Yao et al. Health system-scale language models are all-purpose prediction engines. Nature 619(7969), 357–362 (2023).
Peng, Cheng et al. A study of generative large language model for medical research and healthcare. NPJ Digit. Med. 6(1), 210 (2023).
Zhang, Kai, Zhou, Rong, Adhikarla, Eashan, Yan, Zhiling, Liu, Yixin, Yu, Jun, Liu, Zhengliang, Chen, Xun, Davison, Brian D, Ren, Hui, et al. A generalist vision–language foundation model for diverse biomedical tasks. Nature Medicine, 1–13, (2024).
Hager, Paul et al. Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nat. Med. 30(9), 2613–2622 (2024).
Williams, Christopher YK., Miao, Brenda Y., Kornblith, Aaron E. & Butte, Atul J. Evaluating the use of large language models to provide clinical recommendations in the emergency department. Nat. Commun. 15(1), 8236 (2024).
Kim, Jonathan, et al. “Limitations of large language models in clinical problem-solving arising from inflexible reasoning.” Scientific reports 15.1 (2025): 39426.
AAMC Physician Workforce Data Dashboard specialty percentages were used to compute relative proportion of medical specialties. This provides a population-based representation of generalist core questions from internal medicine and family medicine and specialty board questions. The union of subspecialty topics within internal medicine and family medicine were obtained from American Board of Family Medicine and American Board of Internal Medicine Board topic distribution sites.